gen ai - UX Case Study
UX Case Study
UX Case Study
UX Case Study
UX Case Study
Model Migration as a Lifecycle Problem
Amazon Bedrock, 2026
Enabling enterprises to migrate models without losing trust, quality, or control
PROBLEM OVERVIEW
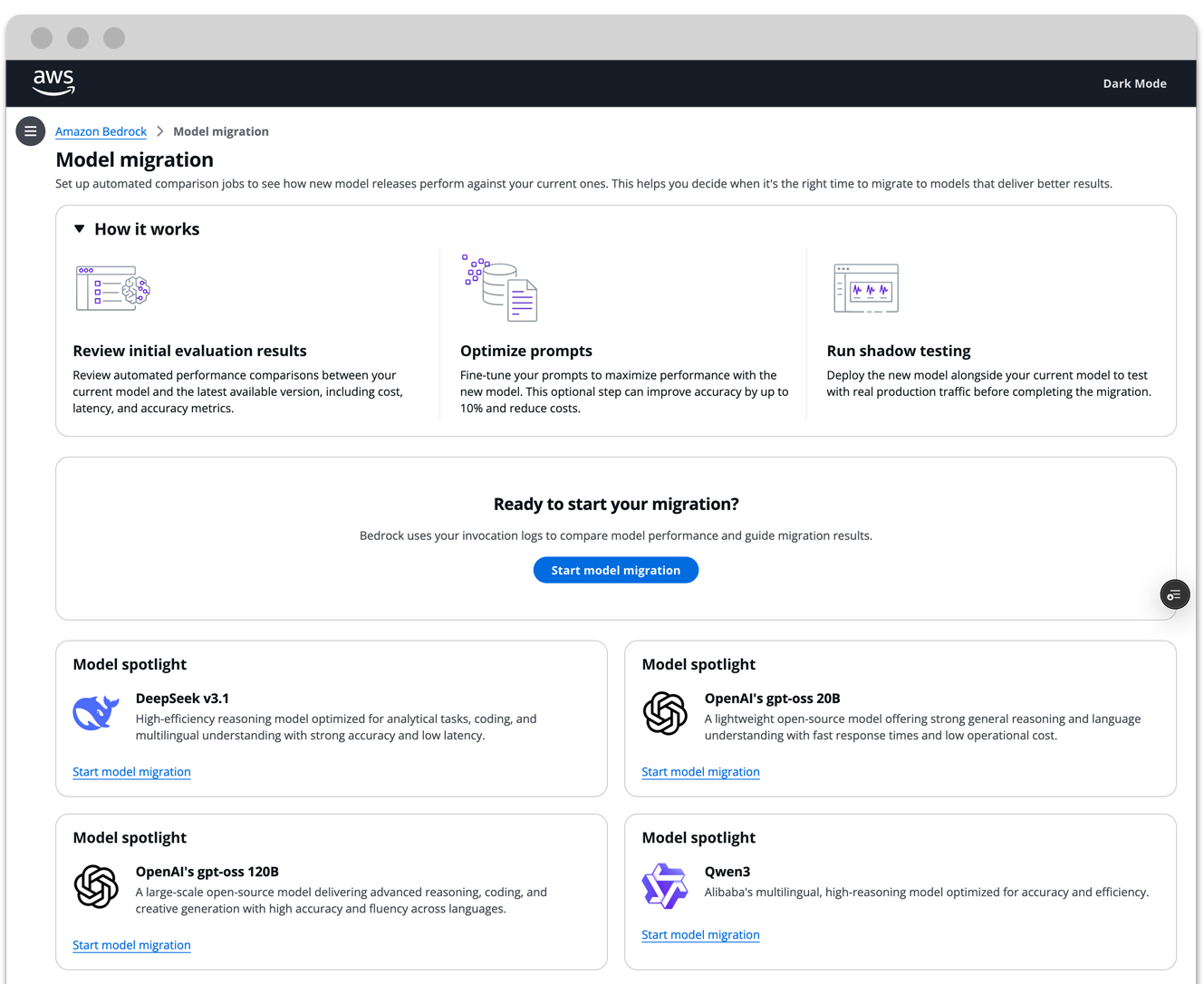
PROJECT OVERVIEW
PROJECT Overview
When AI models get updated, the prompts that power enterprise products can break in ways that are hard to predict. Fixing them could take thousands of hours.
I designed a centralized tool that gives enterprise teams visibility and control over the migration process, reducing a months-long operational effort into a guided, measurable workflow.
When AI models get updated, the prompts that power enterprise products can break in ways that are hard to predict. Fixing them could take thousands of hours.
I designed a centralized tool that gives enterprise teams visibility and control over the migration process, reducing a months-long operational effort into a guided, measurable workflow.
When AI models get updated, the prompts that power enterprise products can break in ways that are hard to predict. Fixing them could take thousands of hours.
I designed a centralized tool that gives enterprise teams visibility and control over the migration process, reducing a months-long operational effort into a guided, measurable workflow.
Interactive prototype
I built an interactive prototype, using the Cloudscape Design System and Claude Code to demonstrate functional fidelity. With this prototype my stakeholders could experience real interaction patterns rather than static screens.
In the prototype, you'll be able to go through each screen of the experience and interact with the data and dashboards. For tech details, view the ReadMe on my Github.
Note: This is a functional UI prototype. No real data is processed. Job flows, evaluation results, and shadow testing outputs are simulated to demonstrate interaction patterns and workflow states.
Design thesis and principles
DESIGN THESIS
AI systems and agents are only trustworthy when change is explicit.
This work treated model migration as a change-management problem, not an optimization exercise. The primary failure modes designed against were silent behavior change, inefficient token utilization, and unexplainable shifts in output quality.
PRINCIPLES THAT SHAPED EVERY DECISION
- Show what changed
- Safety is the default
- System provides the evidence
- Humans decide the next step
Who I designed for
Model migration sits between system reliability and response quality. I designed for two primary personas.
BEDROCK DEVELOPER

Primary focus
Building reliable AI applications in production.
Responsibilities
- Application performance under real user inputs
- Token usage and cost management
- Handling large documents and context limits
- Stability during upgrades
Needs
- Clear performance and cost comparisons
- Confidence that behavior will not regress
- Safe rollout paths to production
PROMPT ENGINEER

Primary focus
Getting the best possible responses from the model.
Responsibilities
- Prompt design and iteration
- Quality evaluation across models
- Working within token and instruction limits
- Balancing detail with response flexibility
Needs
- Side-by-side output comparisons
- Fast testing workflows
- Evidence that quality improves, not degrades
Shared Constraints
Both personas operate within model limits, balance cost and performance, and need validation before committing to a model change.
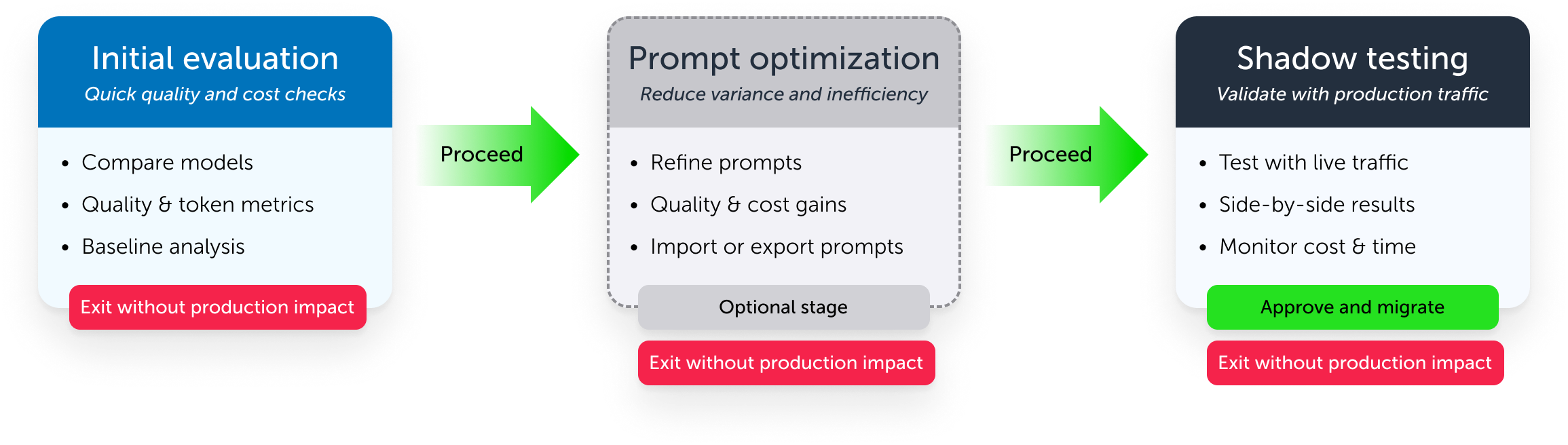
The system, not the screens
Model migration was designed as a decision lifecycle, not a workflow. The lifecycle consisted of three stages that progressively increased confidence while making cost and risk legible.
GUARDRAILS DESIGNED INTO EVERY STAGE
- Users can exit without irreversible impact
- Dynamic and integrated cost calculation
- If an error or failur occurs, stages can be retried
- Mandatory evaluation acts as a guardrail against premature production exposure
- The process keeps responsibility explicit: the system provides evidence, the user decides
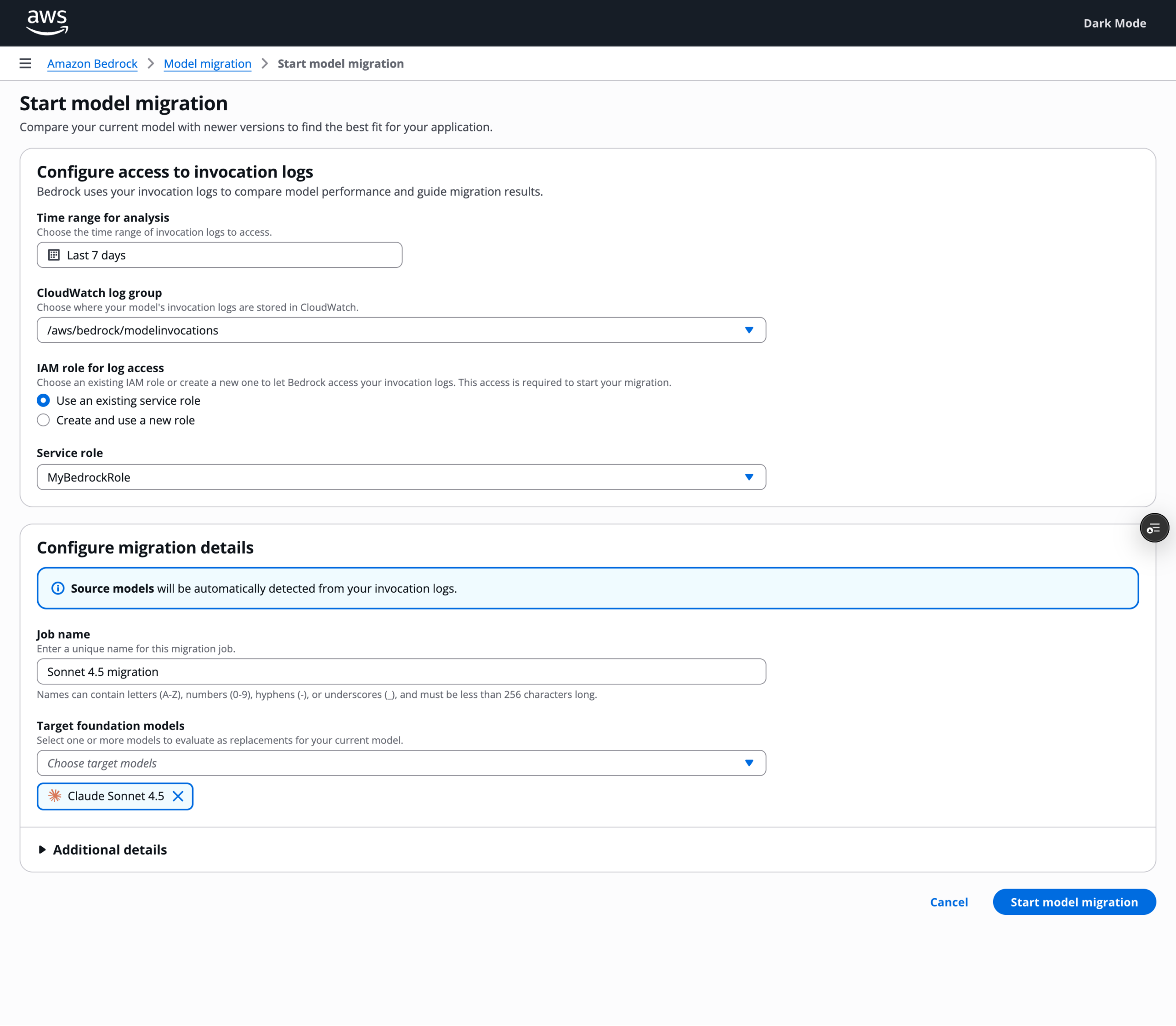
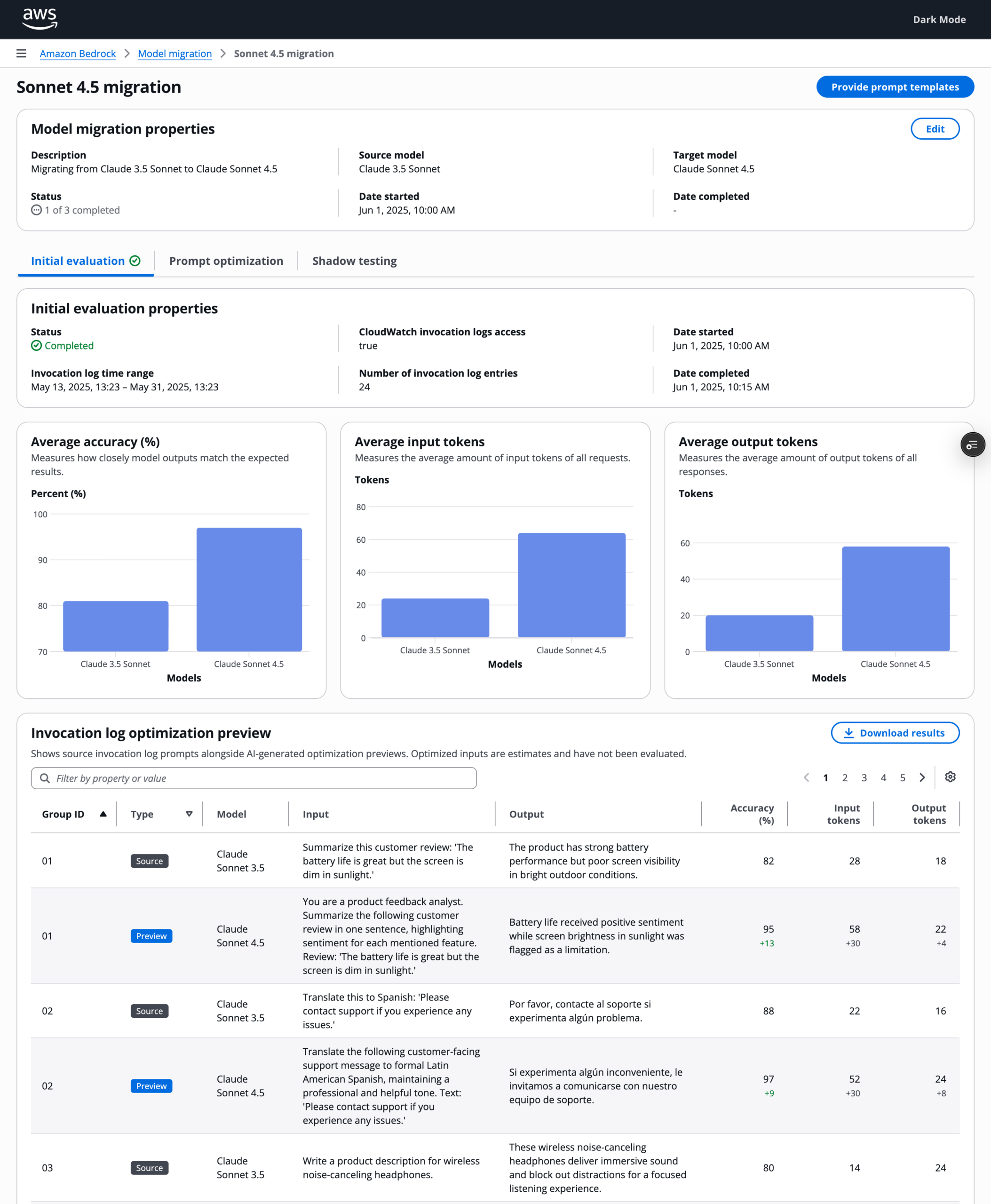
Stage 1: Initial evaluation
To start model migration, my users have to provide: invocation log data from their app (system logs of what an AI did and what the result was) and the models they want to target.
When they start the job, the system performs an Initial Evaluation to compare their source and selected target model performance. This stage acts as a quick decision point if model migration is worth moving forward.
WHAT USERS NEED HERE
- Fast signal on relative quality and token use
- Clear baselines and comparison metrics
- A decision point: proceed or stop
The results screen surfaces performance measurements side-by-side. In this example, Claude Sonnet 4.5 shows higher accuracy and significantly lower latency and cost than Sonnet 3.5. The invocation log table below lets engineers drill into individual prompt pairs, seeing the source and optimized outputs side by side with accuracy deltas at the prompt level. Change is visible. My user decides whether the signal is strong enough to proceed.
Stage 2: Prompt optimization
My users have a variety of methods to provide prompt templates to the system. They can use our system to perform prompt optimization, or skip directly to shadow testing.
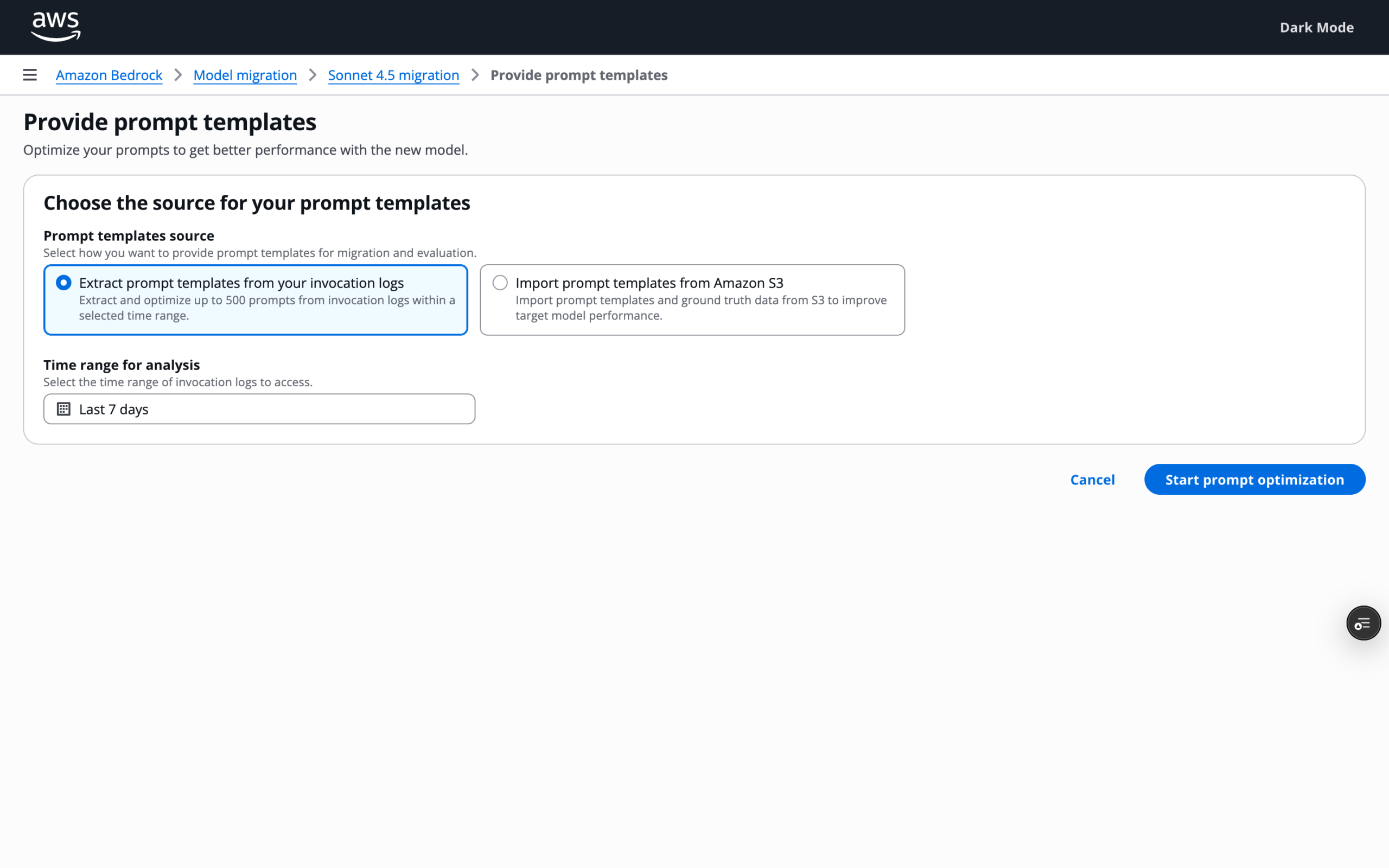
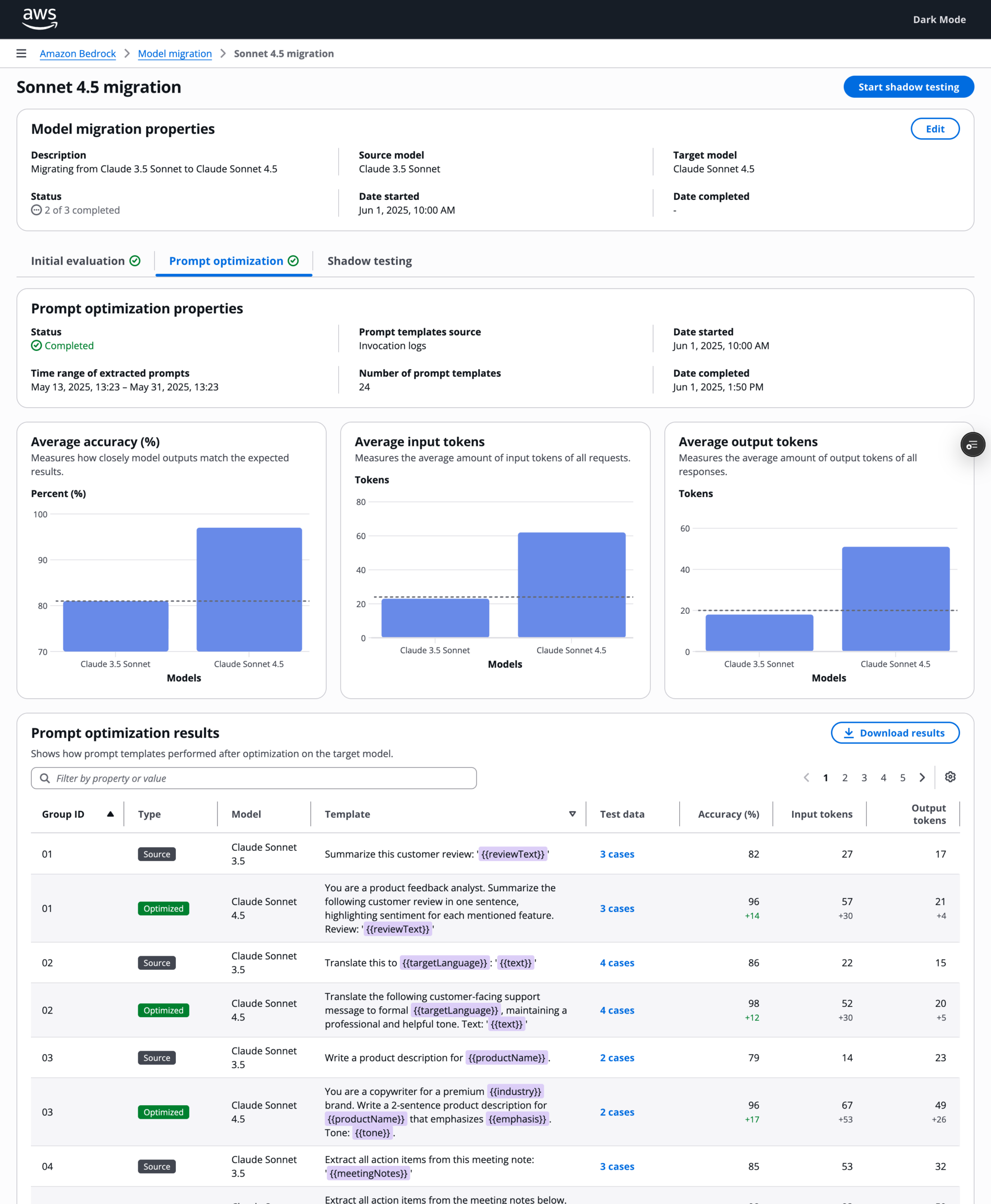
The goal of this stage is to improve relative quality and cost efficiency before deeper investment. Optimization is a lever, not a requirement, and should not block teams that want to evaluate with their own methods.
WHAT USERS NEED HERE
- A clear promise: what optimization can and cannot do
- Visibility into which prompts improved and by how much
- The ability to import results if they optimize externally
Stage 3: Shadow testing
After providing optimized prompt templates and test data, users configure a traffic sample and duration to begin shadow testing. It produces production-like evidence without production impact.
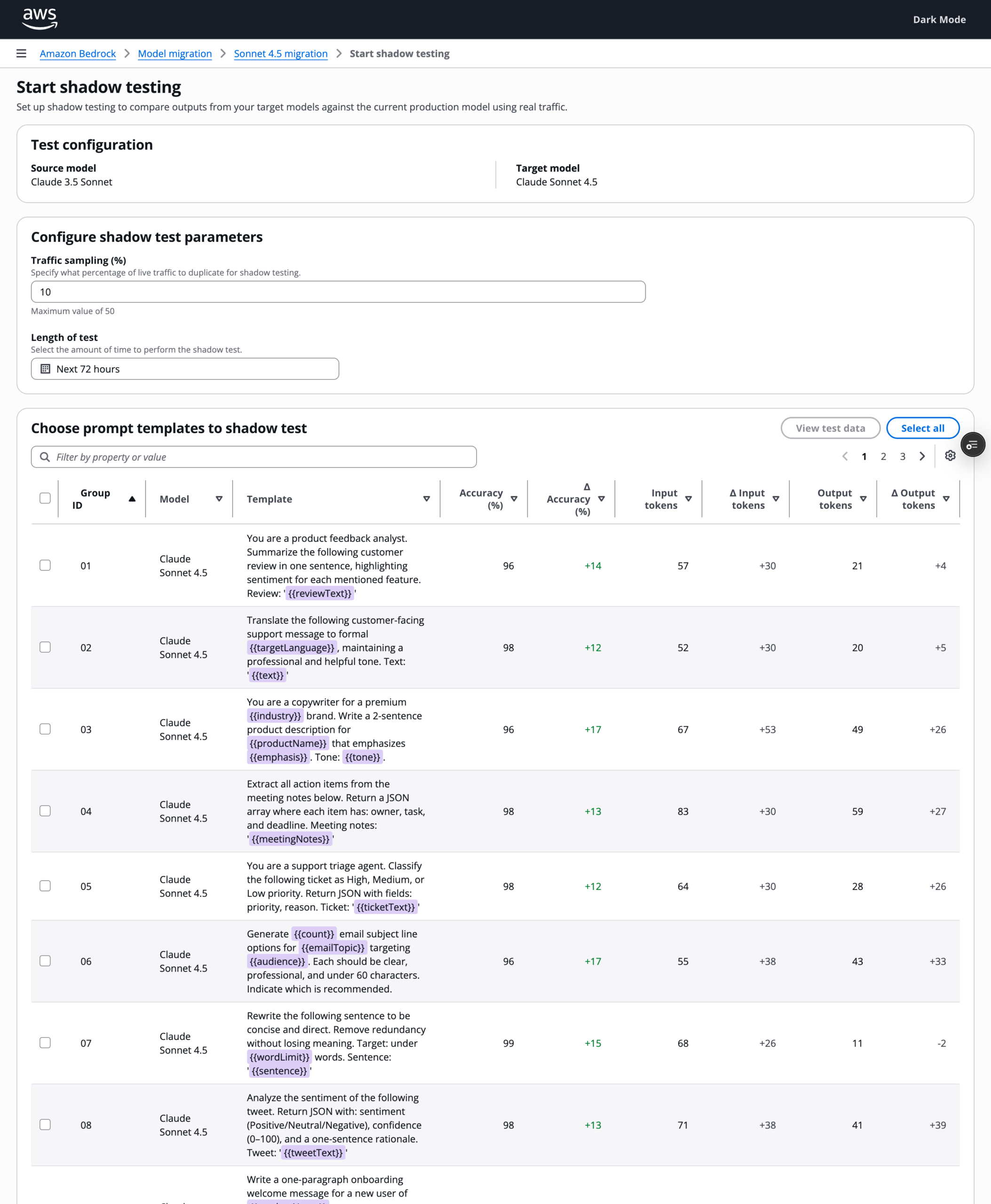
WHAT USERS NEED HERE
- A controlled time window and clear cost expectations
- Streaming results so they can stop early
- Side-by-side diffs for outputs and key metrics
Shadow testing runs the target models against live production traffic in parallel with the current model. Results stream in real time so engineers can monitor performance as the test runs. At the end, engineers make the final migration decision based on what they see.
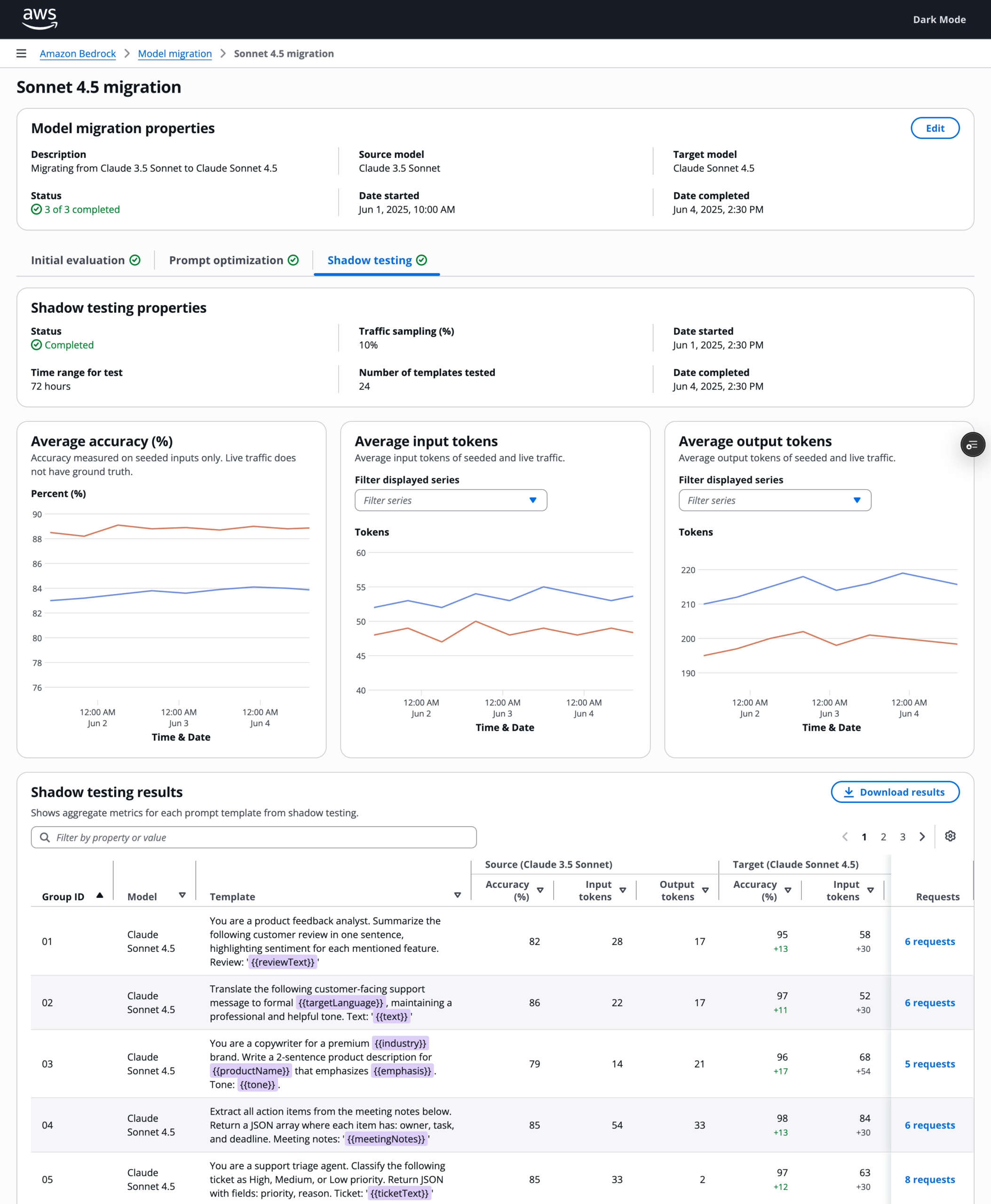
Results
Enterprise customers who reviewed the system reported it would significantly reduce the chaos they had experienced with model migrations. A process that was too risky to run repeatedly became a controlled, repeatable one-to-two week lifecycle.
Portfolio
AWS Glue Job Monitoring DashboardMonitoring dashboard for AWS Glue ETL pipelines
AWS Glue StudioDesigning a configuration-driven data pipeline builder for enterprise scale
PartiQL Editor for Amazon QLDBUX Case Study
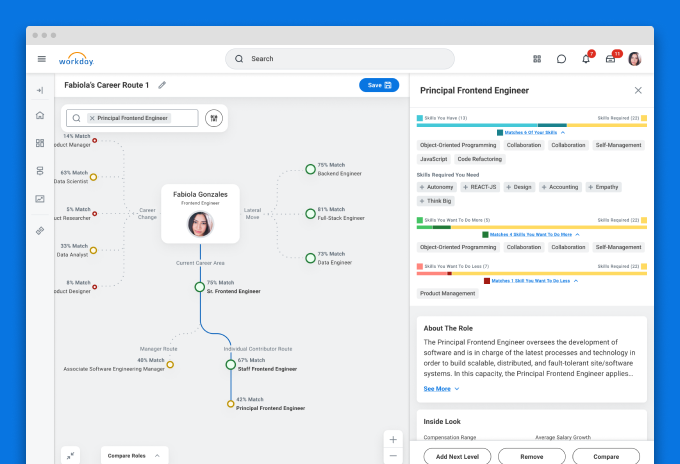
Career exploration for Workday's Career HubDesigning AI-assisted career exploration with human judgment at the center
Enhanced chat for Chase mobileUI-UX design
Transaction details for Chase mobileUX Case study

UI for James Bond 007: World of espionageDesign system
Chase mobileUI-UX Design