OVERVIEW
AWS Glue Studio was created to help enterprise teams build, manage, and operate data pipelines without requiring deep infrastructure expertise. The design challenge was not inventing new data systems, but enabling configuration-heavy workflows that remained correct, predictable, and scalable across teams and use cases.
My role focused on designing abstractions, guardrails, and workflows that allowed users to assemble complex pipelines safely, while preventing invalid configurations and reducing operational risk.
OVERVIEW
AWS Glue Studio was created to help enterprise teams build, manage, and operate data pipelines without requiring deep infrastructure expertise. The design challenge was not inventing new data systems, but enabling configuration-heavy workflows that remained correct, predictable, and scalable across teams and use cases.
My role focused on designing abstractions, guardrails, and workflows that allowed users to assemble complex pipelines safely, while preventing invalid configurations and reducing operational risk.
Overview
AWS Glue Studio was created to help enterprise teams build, manage, and operate data pipelines without requiring deep infrastructure expertise. The design challenge was not inventing new data systems, but enabling configuration-heavy workflows that remained correct, predictable, and scalable across teams and use cases.
My role focused on designing abstractions, guardrails, and workflows that allowed users to assemble complex pipelines safely, while preventing invalid configurations and reducing operational risk.
What this demonstrates
- Designing configuration-heavy enterprise platforms
- Balancing flexibility with guardrails
- Enabling non-expert users without exposing unnecessary system complexity
- Scaling interaction patterns across teams and workflows
The problem space
AWS Glue is a managed ETL (Extract, Transfer, & Load) service used by enterprises to process large volumes of data across diverse sources and destinations. As adoption grew, customers needed a way to compose and manage pipelines across teams without relying on deep infrastructure expertise.
Existing workflows required scripting, manual validation, and significant trial and error. This made it difficult for non-expert users to understand dependencies, validate configurations, or predict execution outcomes, especially at enterprise scale.
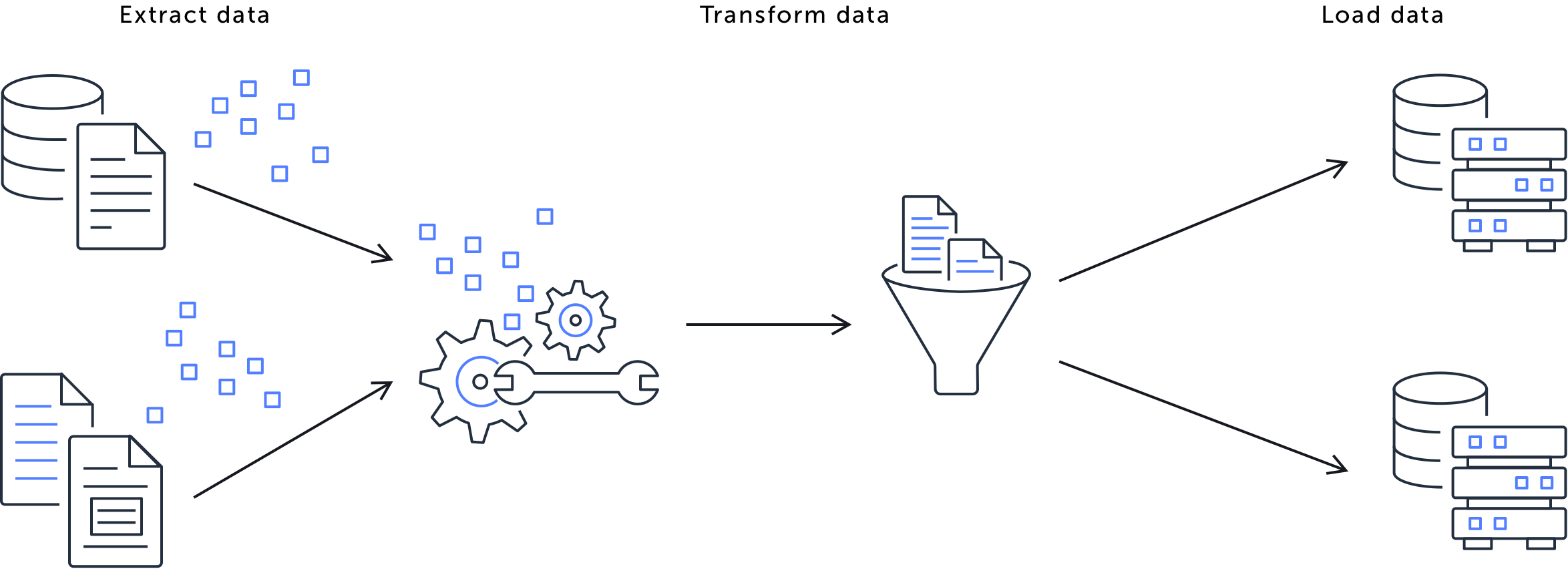
The design problem
How might we enable users to configure complex data pipelines confidently while enforcing constraints that ensure correctness, reliability, and consistency across enterprise environments?
KEY CONSTRAINTS INCLUDED:
- Strict execution dependencies between pipeline steps
- High cost of detecting errors late in execution
- Wide variance in user expertise across teams
- The need to scale patterns across organizations, not individuals
My role
I led UX design for AWS Glue Studio in close partnership with engineering. My focus was on translating complex pipeline behavior into configuration-driven workflows that guided users toward valid, supported patterns.
I was responsible for defining interaction models for pipeline composition, designing configuration and validation flows, and ensuring the UI accurately reflected backend constraints without exposing unnecessary system internals.
Who I designed for
Glue Studio serves users across a wide ETL skill spectrum, from advanced coders to no-code analysts. The challenge was designing a single authoring experience that scales across that range.
DATA ENGINEER (Advanced coder)

Primary focus
Designing scalable, production-grade data pipelines.
Responsibilities
- Complex transformations and performance optimization
- Infrastructure reliability and orchestration
- Debugging and cost control
Needs
- Full control and code-level flexibility
- Transparency into generated logic
- The ability to extend beyond abstractions
DATA SCIENTIST (Low-code)

Primary focus
Preparing and transforming data for modeling and production use.
Responsibilities
- Data shaping and feature preparation
- Iterative experimentation
- Translating business questions into pipelines
Needs
- Visual authoring with guardrails
- Reduced setup overhead
- Clear mapping between steps and execution
DATA ANALYST (No-code)

Primary focus
Extracting insights to drive business decisions.
Responsibilities
- Examining trends and patterns
- Delivering clear outputs to stakeholders
Needs
- Simplified workflow creation
- Minimal configuration
- Confidence that pipelines will run correctly
Key design principles
CONFIGURATION OVER CONSTRUCTION
Users should configure intent, not construct systems from scratch.
- Structured steps instead of free-form scripting
- Clear mappings between user choices and supported execution paths
- Reduced reliance on expert knowledge
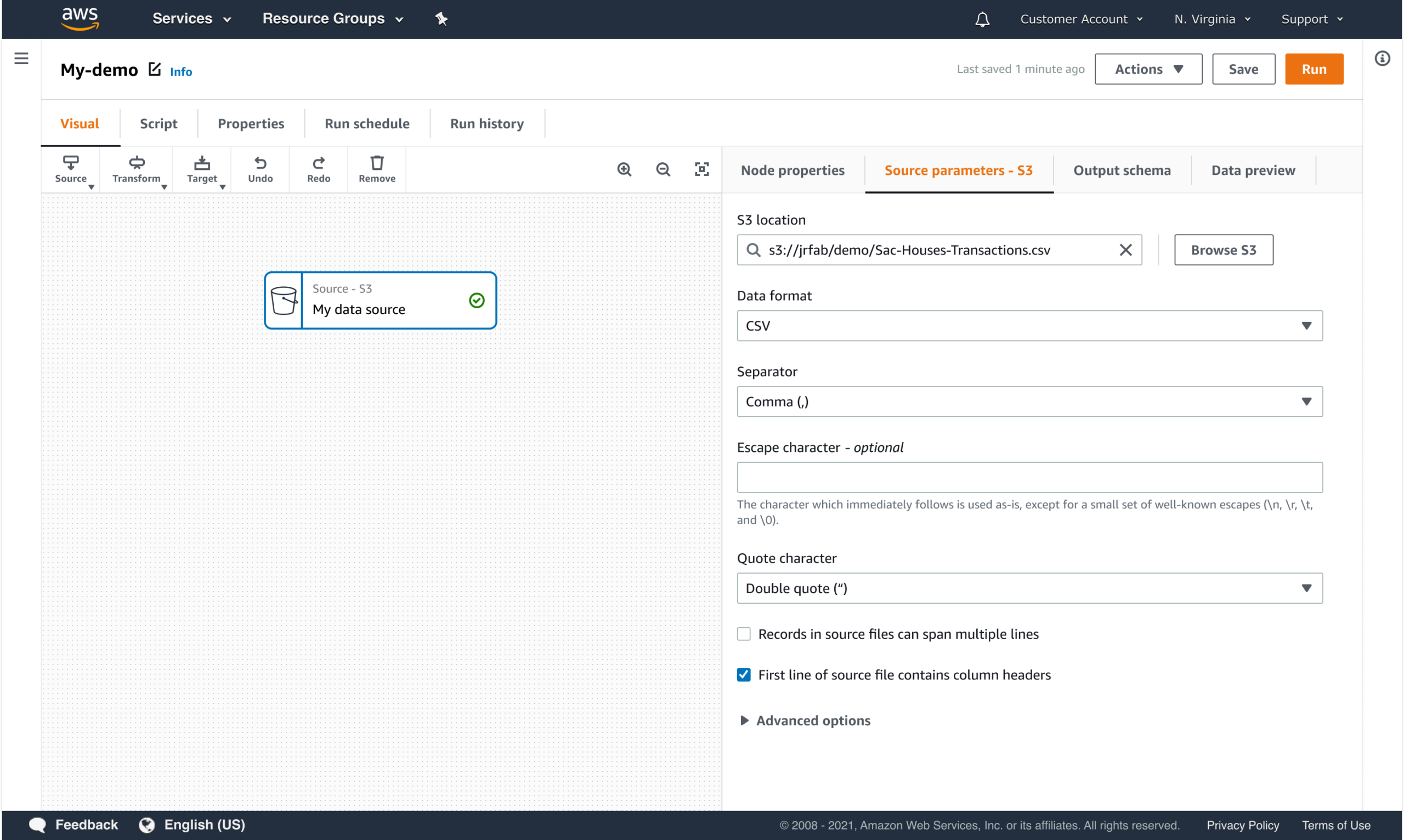
GUARDRAILS AND VALIDATION BUILT INTO THE FLOW
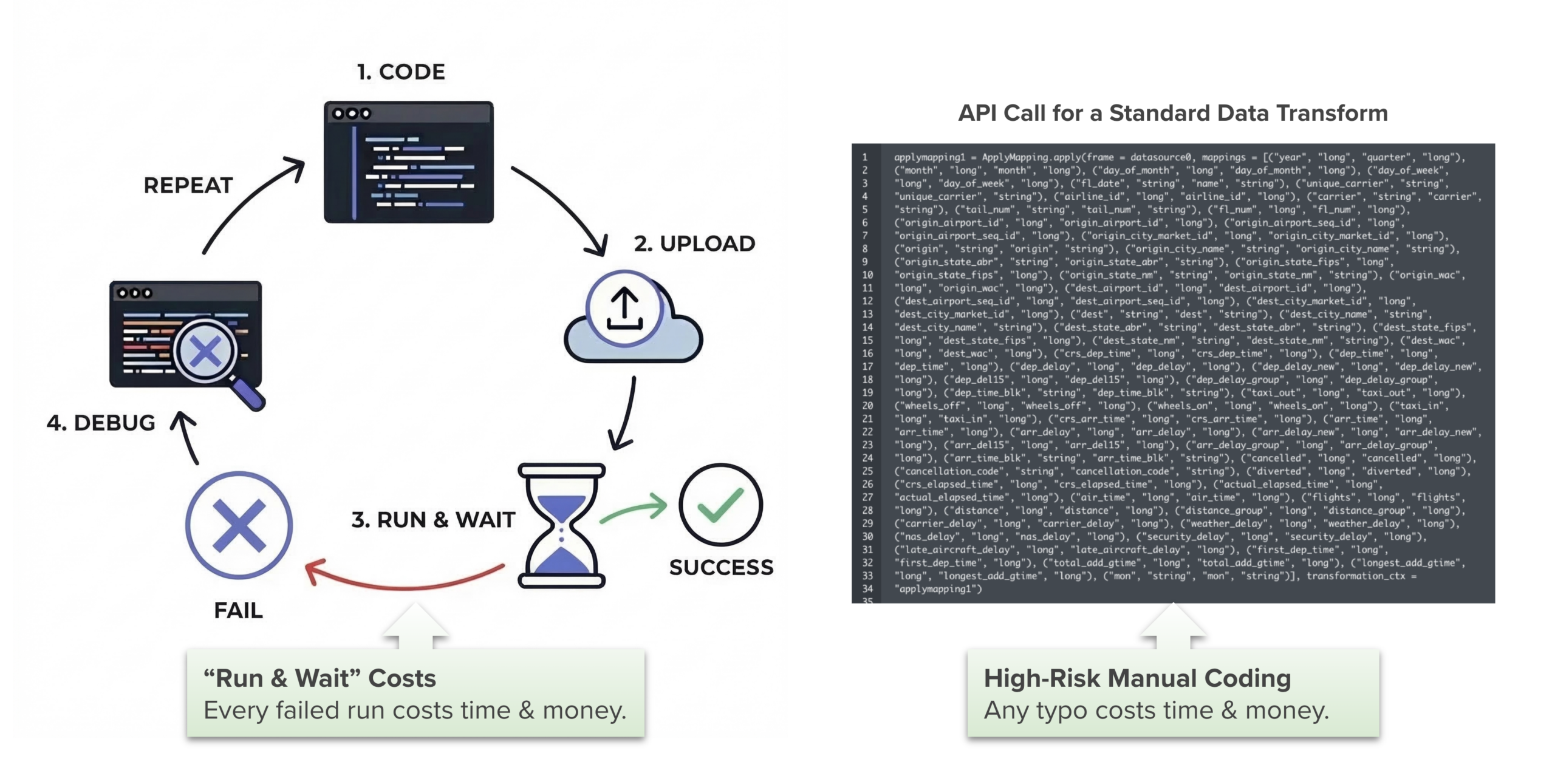
Constraints and validation were integrated directly into the configuration experience to prevent invalid states early and reduce downstream failures.
- Invalid configurations prevented before execution
- Feedback surfaced at the moment issues were introduced
- Clear guidance on what needs to change and why
- No silent failures or hidden constraints
This approach allowed users to move faster with confidence while maintaining enterprise standards for correctness and reliability.
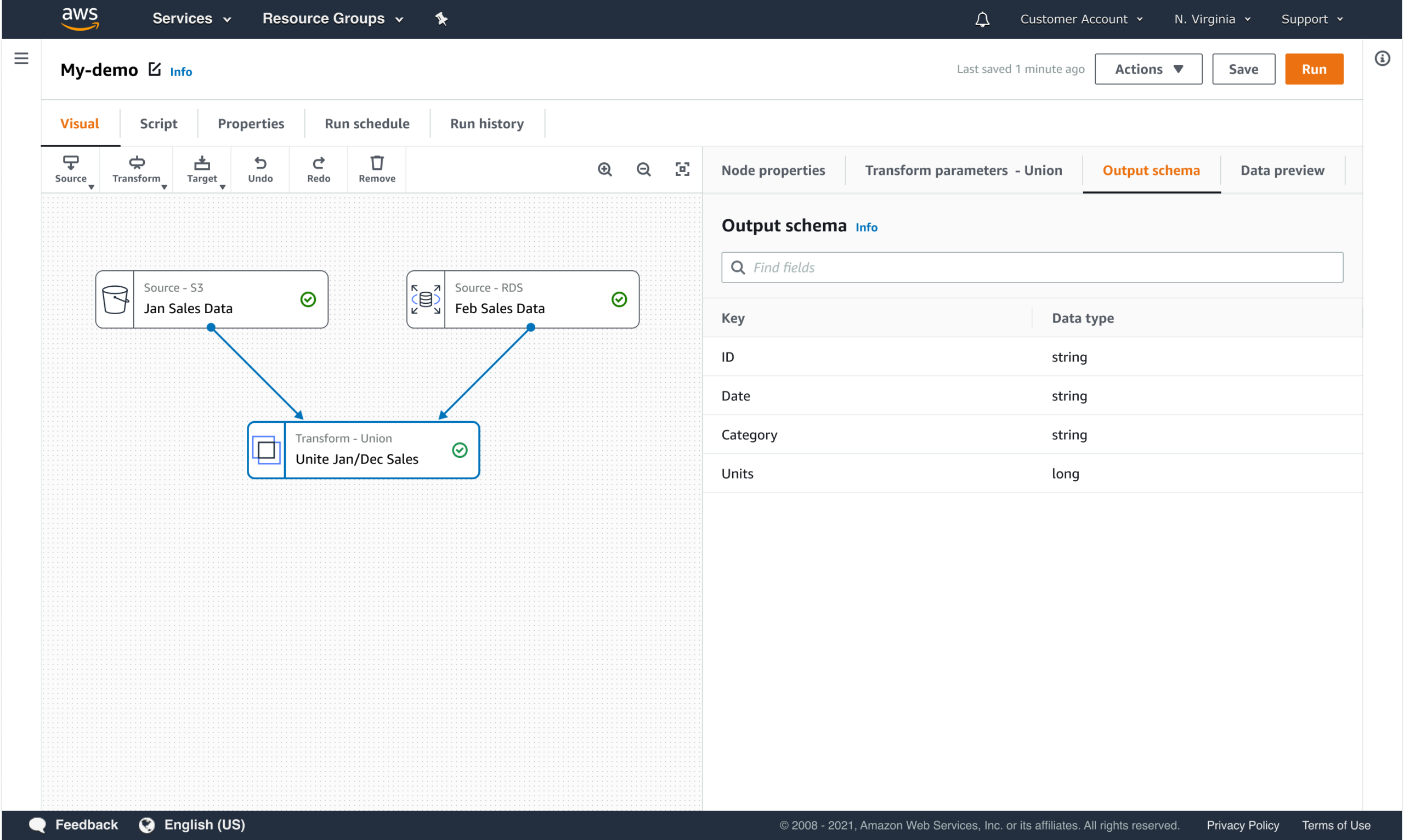
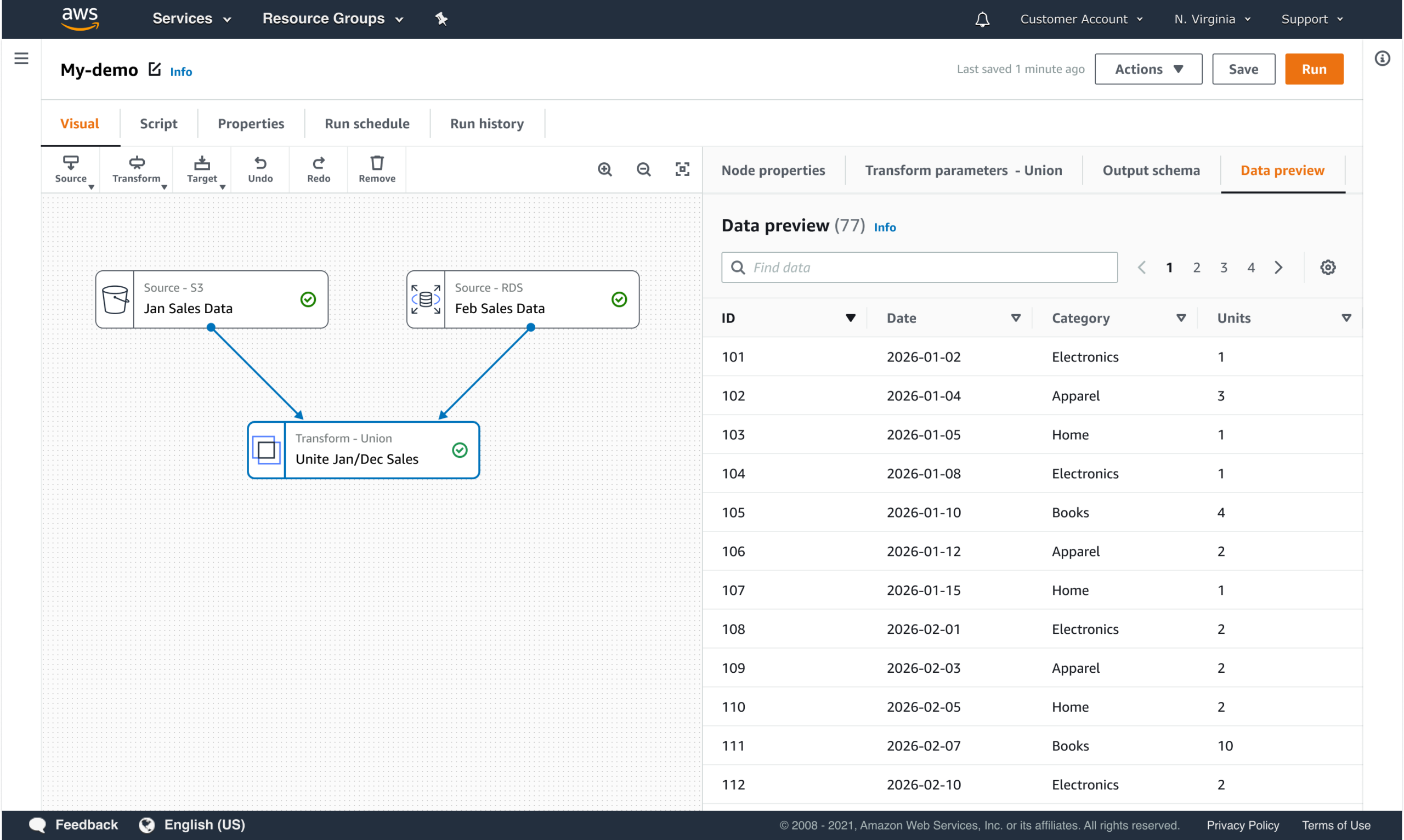
PROGRESSIVE DISCLOSURE OF COMPLEXITY
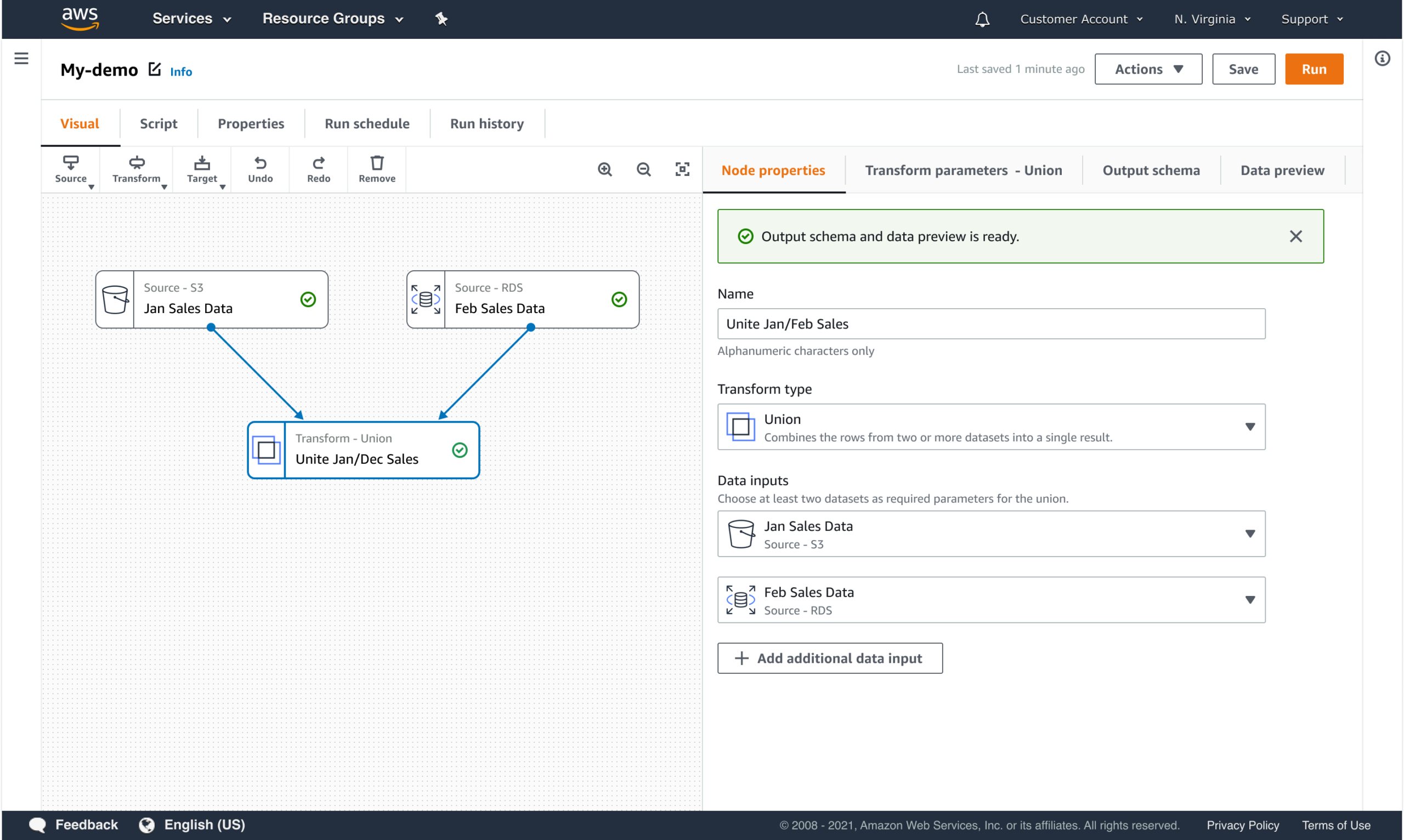
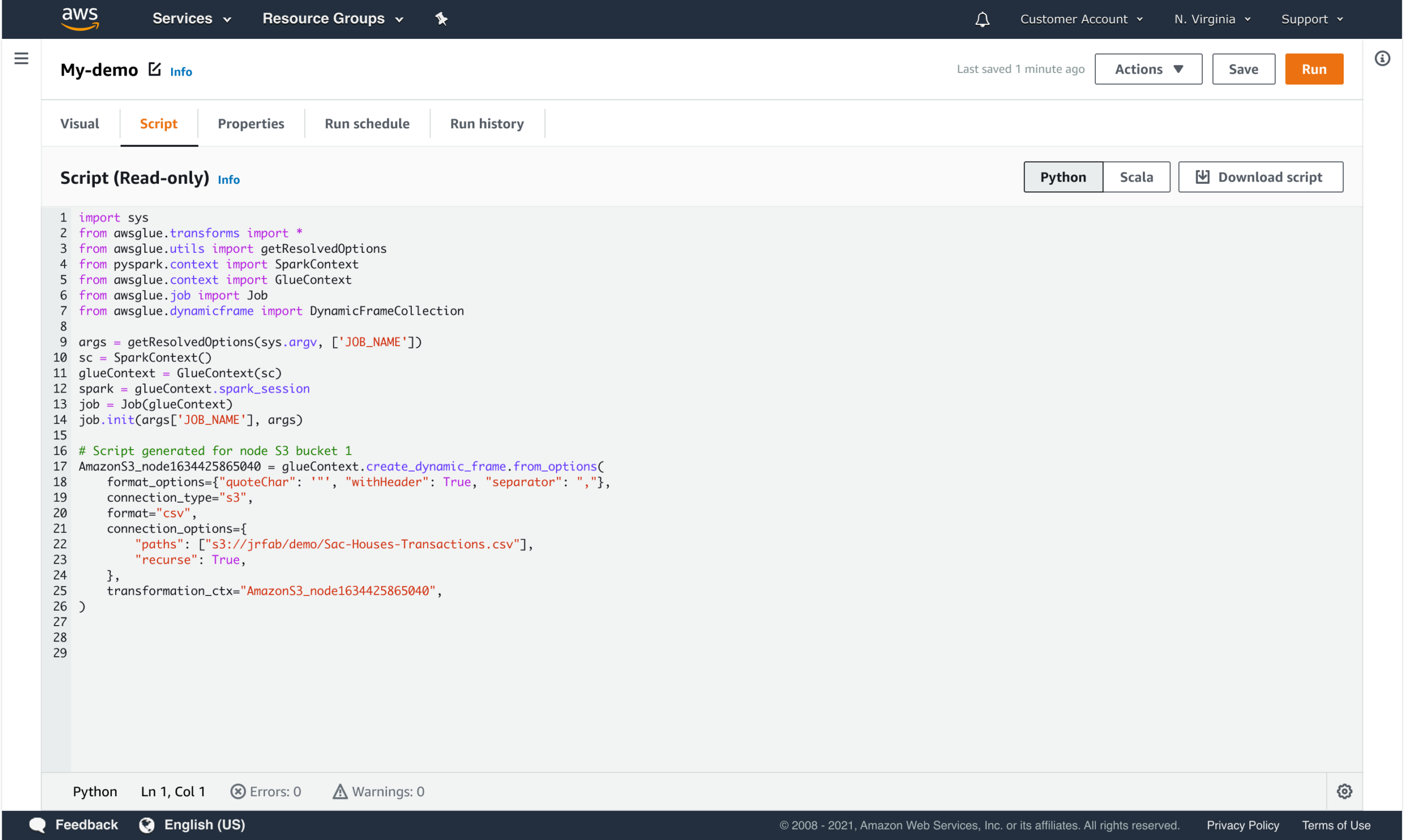
The interface reveals detail when users need it, not all at once.
- Defaults for common use cases
- Advanced options revealed contextually
- Dependencies surfaced when they matter
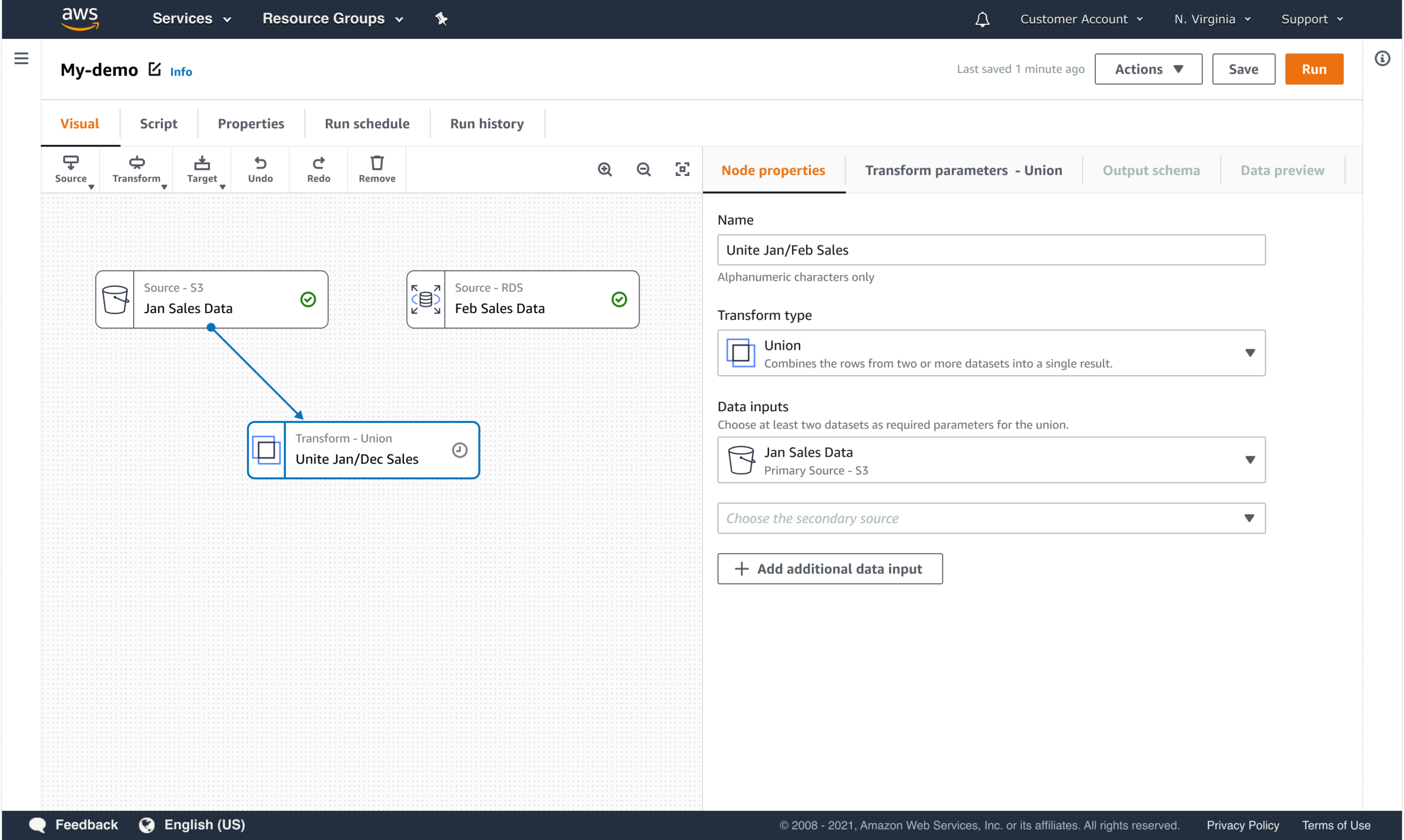
WORKFLOW COMPOSITION
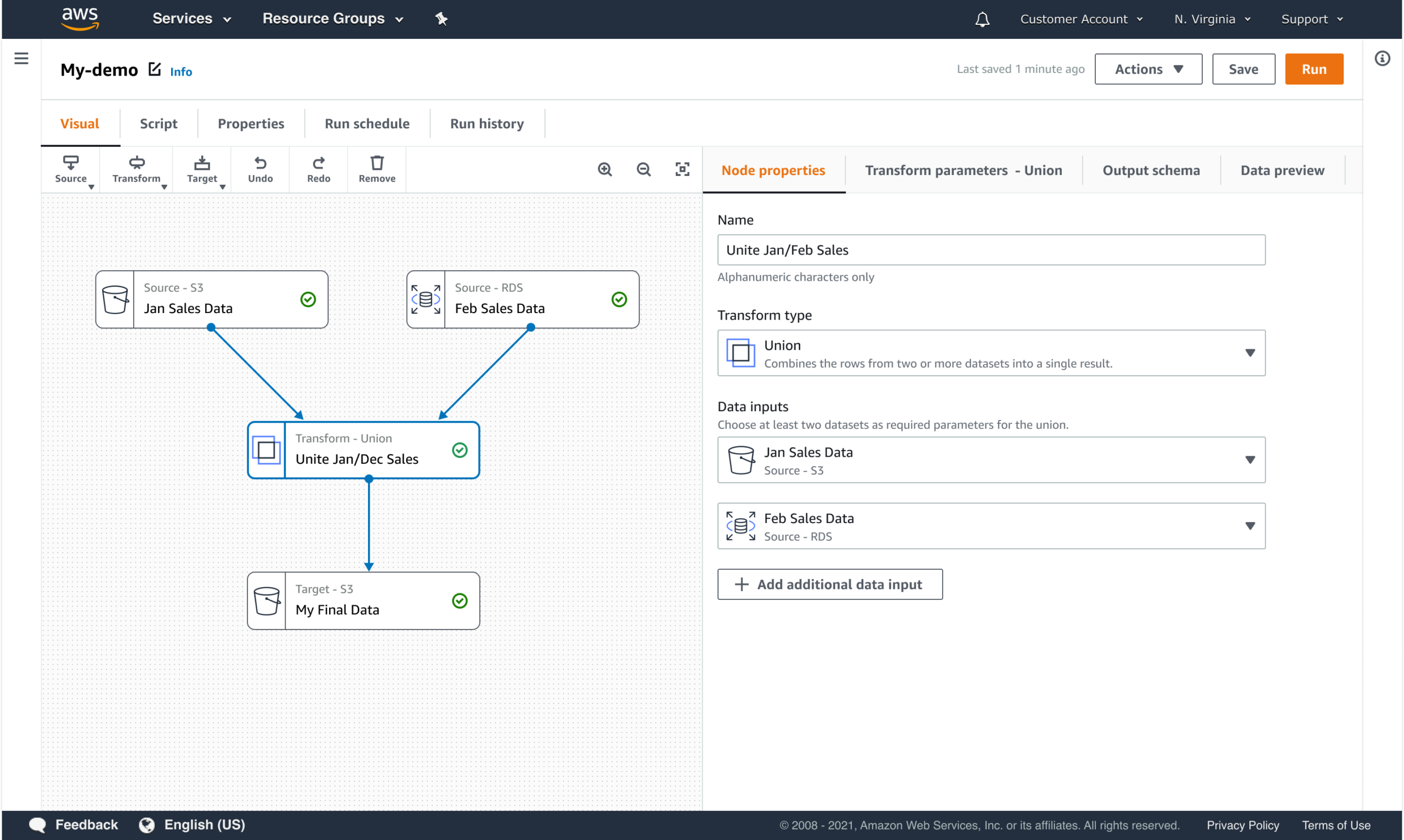
Users assemble pipelines by composing structured steps that define both execution order and operational expectations.
Workflow composition was designed to create a shared mental model that carries through from configuration to execution. By making structure and dependencies explicit up front, users could more easily understand pipeline behavior while it was running, not just when it was being built.
This approach:
- Makes dependencies and execution order explicit
- Reduces configuration errors before runtime
- Supports reuse and consistency across teams
- Enables clearer monitoring and troubleshooting during execution
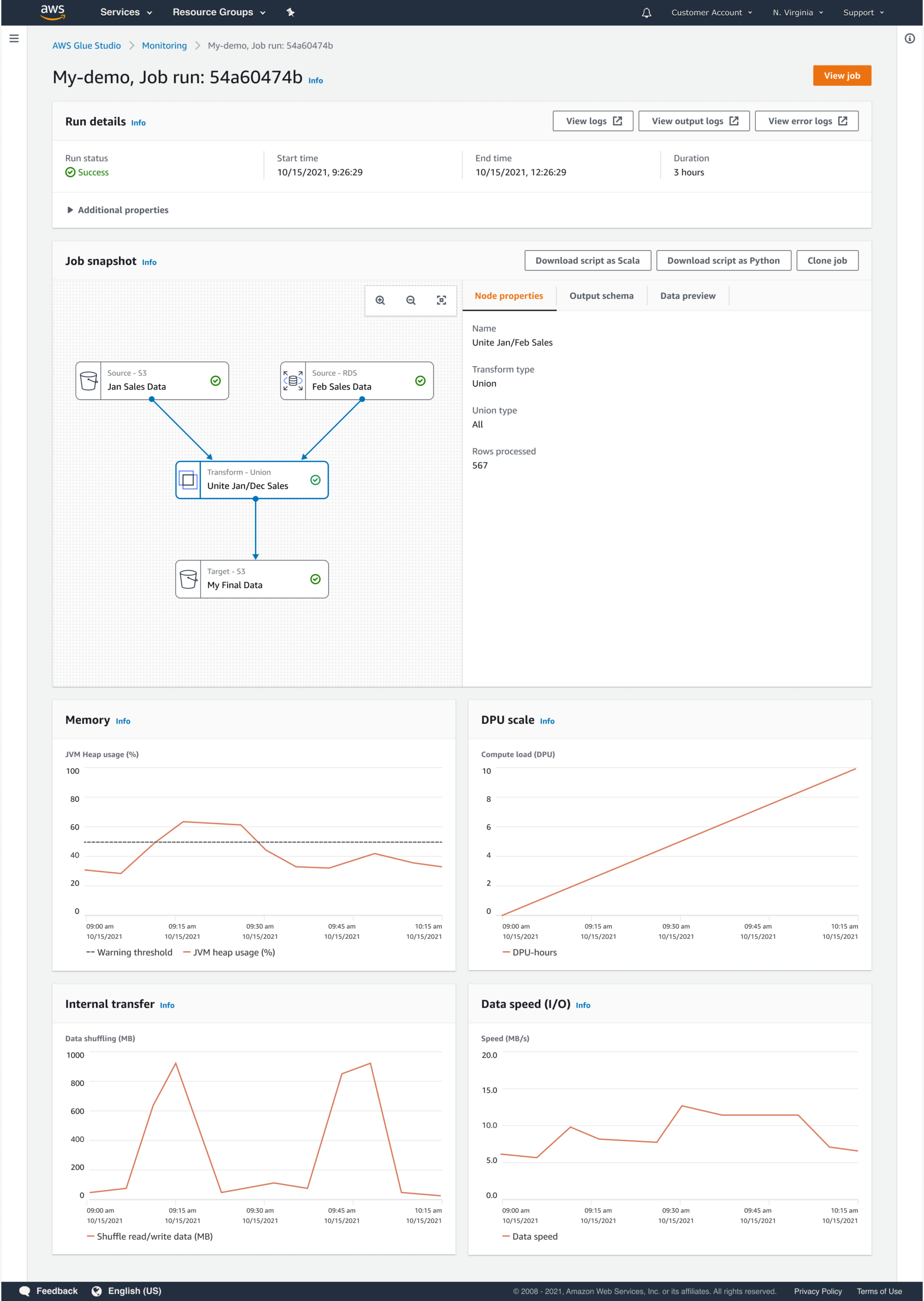
Run Details provide a snapshot of the configuration, time-series performance metrics, and direct links to CloudWatch logs for deep troubleshooting
Outcomes
The resulting experience enabled a broader set of users to build and manage data pipelines confidently while maintaining enterprise standards for correctness and reliability.
Key outcomes included:
- Reduced dependency on specialized expertise
- Faster time-to-value for new users
- More consistent configurations across teams
- Scalable interaction patterns reused across workflows
Reflection
Designing Glue Studio reinforced the importance of treating configuration as a first-class UX problem. Enterprise platforms succeed when abstraction is deliberate, constraints are surfaced at the right moments, and users are guided toward success without being overwhelmed by system internals.
This project shaped how I approach enterprise enablement: not by hiding complexity entirely, but by making it operable.
Portfolio
Model Migration as a Lifecycle ProblemEnabling enterprises to migrate models without losing trust, quality, or control
Career exploration for Workday's Career HubDesigning AI-assisted career exploration with human judgment at the center
Live Ops Alerting DashboardDesigning clarity for real-time operational decision-making
PartiQL Editor for Amazon QLDBUX Case Study
Asurion Virtual AgentUI Design
Enhanced chat for Chase mobileUI-UX design

UI for James Bond 007: World of espionageDesign system
Chase mobileUI-UX Design
Transaction details for Chase mobileUX Case study
Upgrade systems for Rival FireUX case study